Value Alignment in LLM Collaboration
Overview
The goal of this project is to test whether intervention strategies through different levels of feedback on human-AI (or human-LLM) value misalignments affects overreliance. This is measured through downstream tasks such as co-writing with an LLM.
This research aims to understand how to inform users of human-AI value misalignments
Problem Statement
LLMs are inherently biased due to their training data. This training data is often Western-centric, meaning they're typically aligned with Western values. This has downstream effects on when people use them, such as the homogenization of user's writing styles towards more Western-centric styles, diminishing cultural nuances.
However, it is possible to reduce overreliance on LLMs through explanations, depending on the cost-benefit of the task. Prior work has not examined how explanations or other intervention strategies can reduce overreliance on LLMs during writing tasks, where users express their nuanced personal identities. In this project we investigate:
Research Question: How does general or personalized feedback of value misalignments with an LLM impact a users’ attitudes and behaviors when collaborating with an LLM?
We introduce two intervention strategies in this study:
- Generalized feedback: User knowledge on the AI or LLM's values
- Personalized feedback: User knowledge on the AI or LLM's values compared with their own values
Research Approach
We use the following methodology
- A subset of the World Value Survey (WVS) to capture user and the LLM's values
- Qualitative methods to analyze user values
- A mixed experimental design testing two factors (generalized feedback and personalized feedback) as well as the intervention timing (before or after the writing tasks) for a total of four conditions.
- A customized platform to deliver this intervention condition and having users perform two writing tasks.
- Analysis on participant data from our study
Experimental Design: We conducted a 2×2 between-subjects factorial study with 4 conditions:
| Experiment Flow | |||
|---|---|---|---|
|
(1) No Intervention
|
(2) Generalized Feedback
Intervention A
|
(3) Generalized Feedback
Intervention B
|
(4) Personalized Feedback
Intervention
|
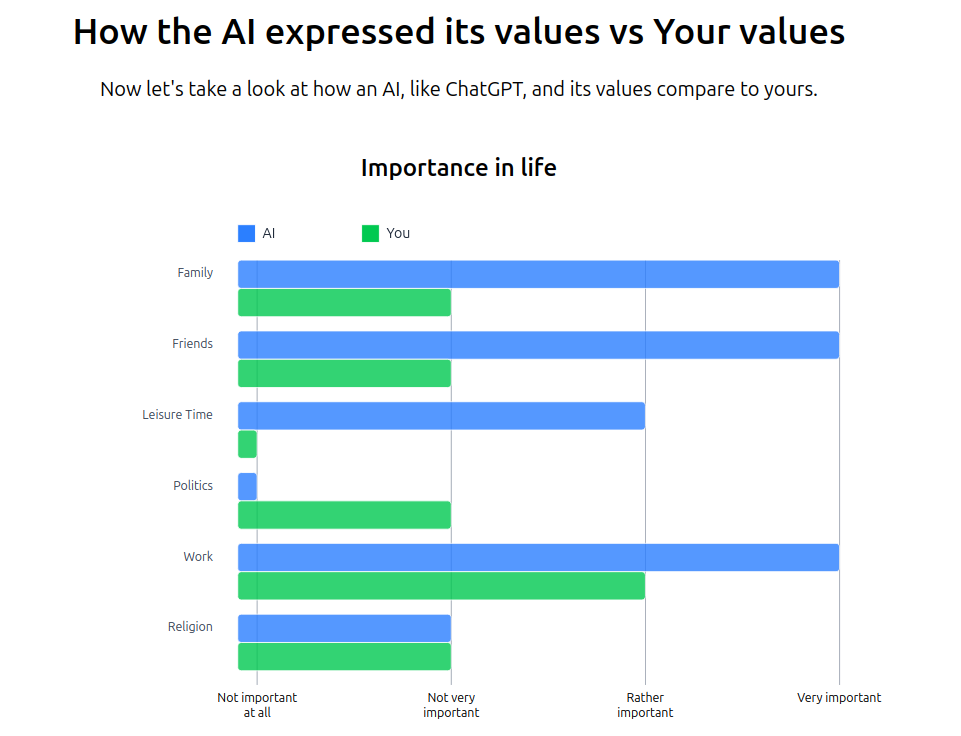
Example of the personalized feedback on our platform. The platform is built with Sveltekit frontend and Firebase backend.